

Summary
Traditionally, NiFi didn’t care about the content of data. A flow file is just “data” whether it’s an image, a text without structure or a text in JSON. This is a powerful characteristic that makes NiFi efficient, data agnostic and suitable for handling unstructured data such as IoT data. However, lot of enterprise use NiFi in use cases that manipulate structured data in different formats: CSV, Json, Avro, etc. To make managing structured data easier, Record Oriented processors have been introduced in NiFi 1.2.
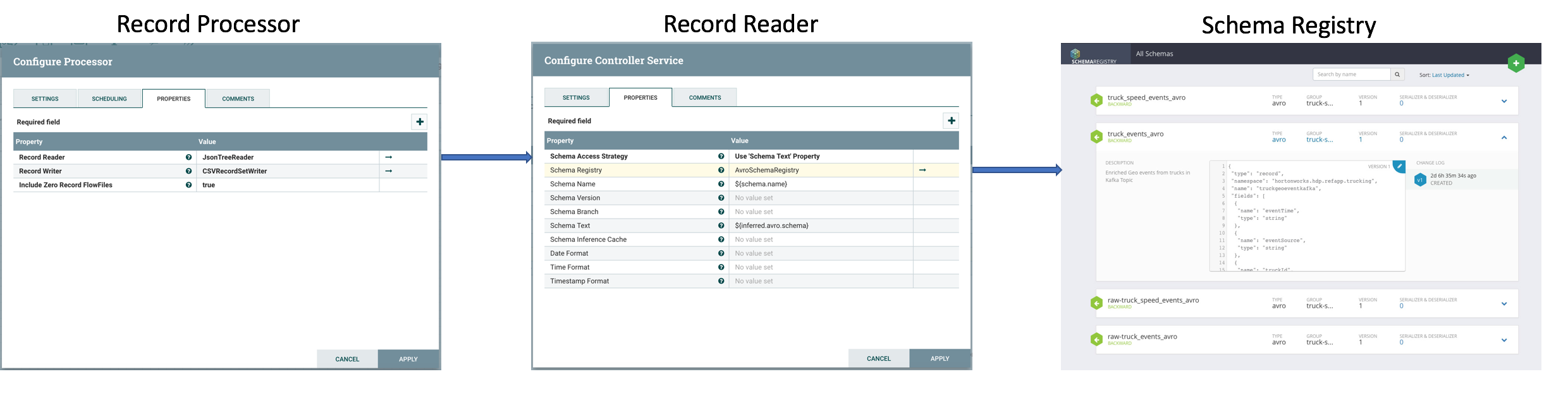
Record oriented processors have been a great addition to NiFi so far. These processors leverage a set of deserializers (Record Readers) and serializers (Record Writters) to efficiently read, transform and write data. The number of record oriented processors is continuously increasing with each NiFi release. To use one of these processors, the user specifies a schema of each data type. Record Readers/Writers offers two main options to define a schema:
- Lookup from one of the three supported schema registries (NiFi, Hortonworks or Confluent). Schema’s references (name and version) are defined in each flow file as an attribute or encoded in the content
- Hard coded in the configuration of the Record Reader/Writer itself
While these two options are great for enforcing schemas lifecycle management, they can make record oriented processors inconvenient to use. This is the case with complex and dynamic schemas. Inferring the schema automatically from the data can make record processors easier to use in these use cases.
Limitations of the InferAvroSchema processor
NiFi has an InferAvroSchema processor for a while. This processor scans the content of a flow file, generate the corresponding schema in Avro format, and add it the content or the attribute of the flow file. By using this processor, the following Record based processors can automatically be used without defining a schema. Indeed, they will get the schema from the flow file directly. Below an example of how to use it:

In this flow, we are generating random JSON data that looks like the below example and we want to convert it to CSV.
1
2
3
4
5
6
7
{
"created_at":"Sat Feb 23 10:35:37 CET 2019",
"id":3961461795499430414,
"text":2669769595141314654,
"timestamp_ms":155091453720,
"id_store":2
}
The InferAvroSchema processor analyses each JSON flow file and stores the inferred schema in the “inferred.avro.schema” attribute.
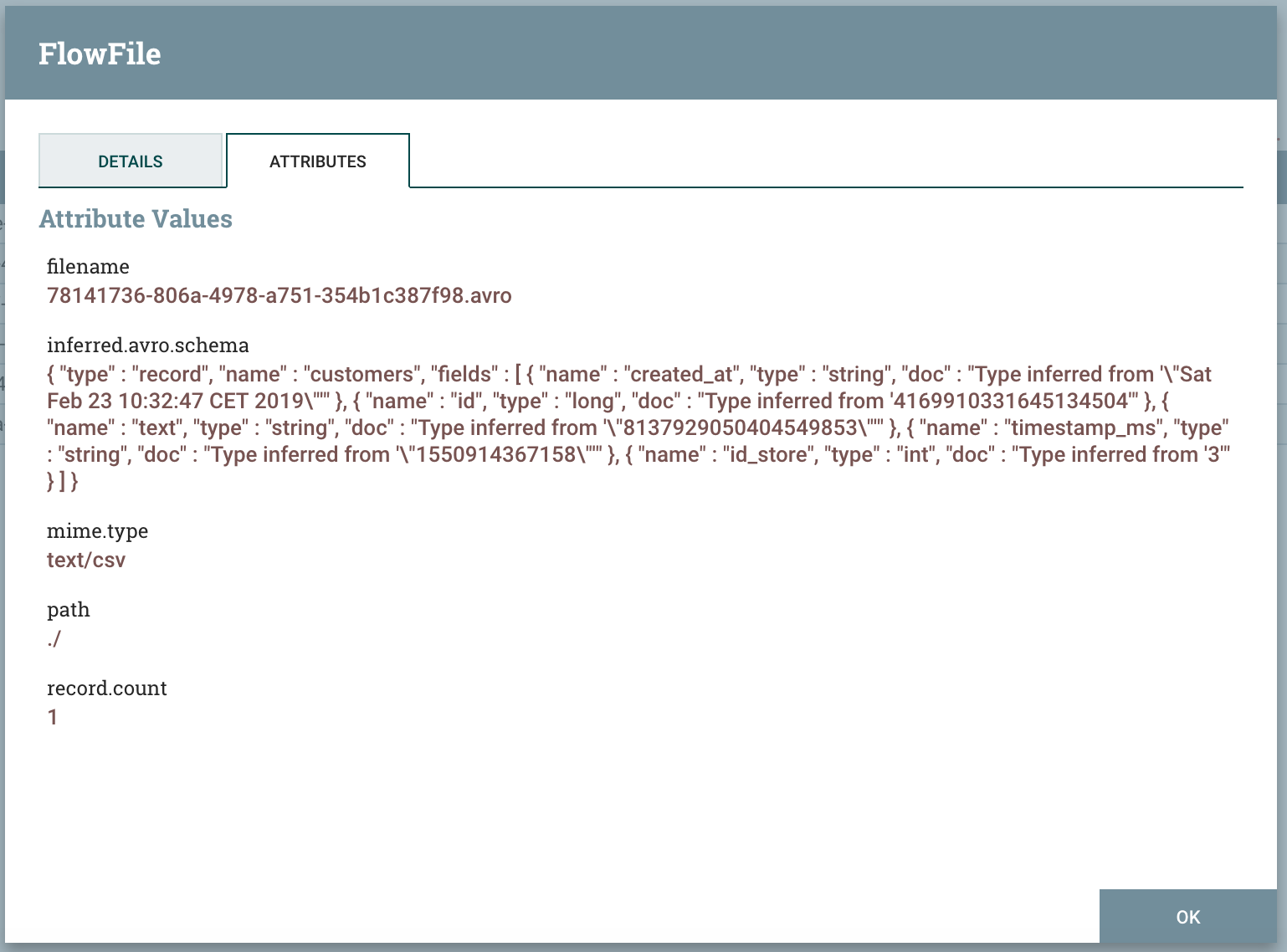
To use the inferred schema in the CSV conversion, we configure the Record Reader used by the ConvertRecord as below. This configurations precises that the schema is defined in the inferred.avro.schema attribute.
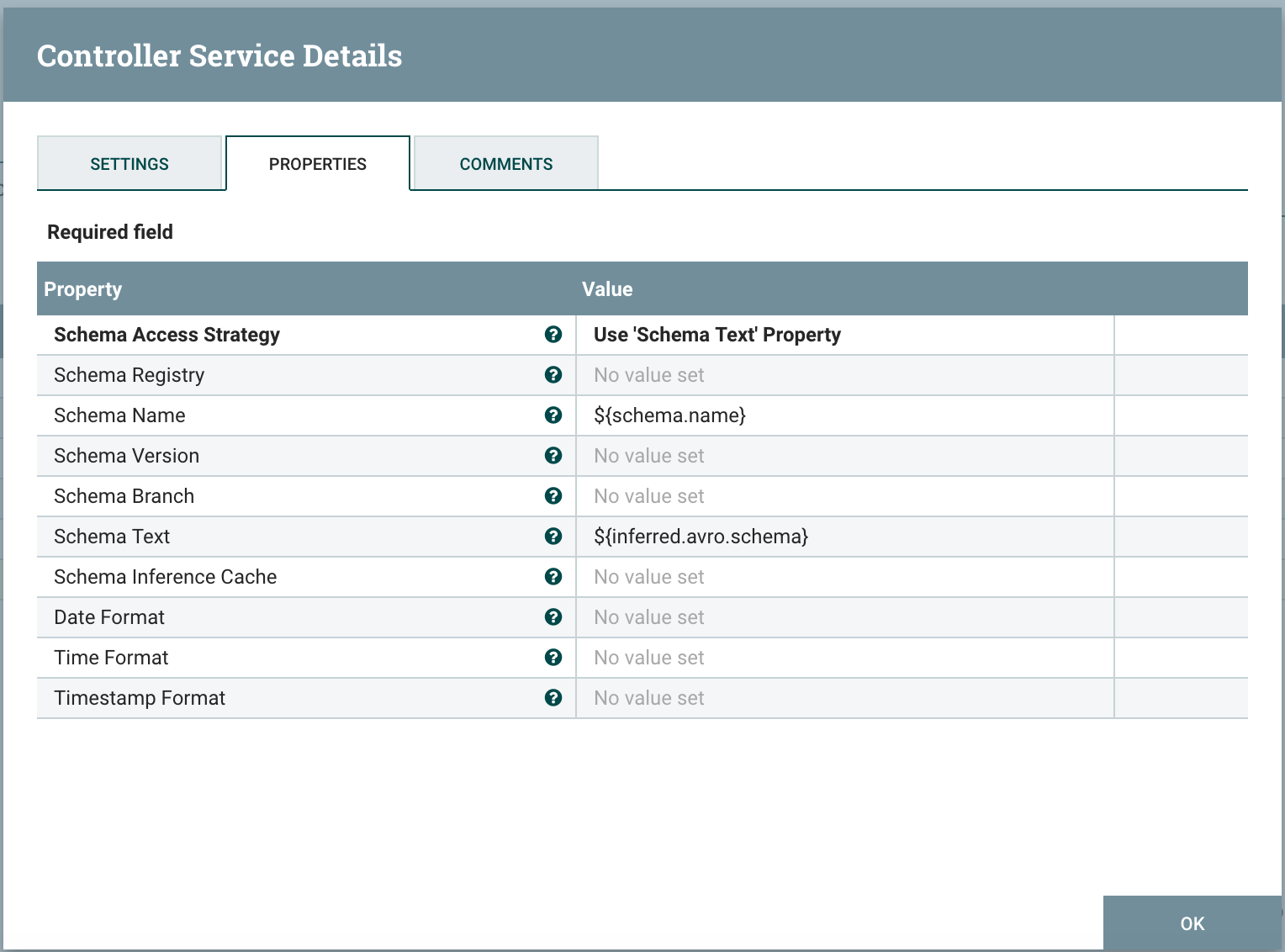
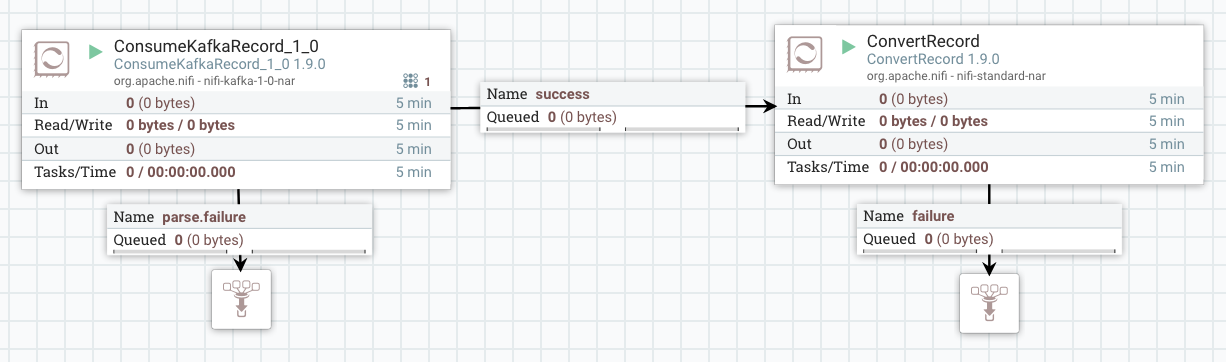
Great, right? we have achieved what we want and we are using Record Processors without manually defining any schema. It is easy and dynamic. However, this approach doesn’t work in all use cases. Imagine you are reading data from Kafka or from a Database and would like to use a Record Based processor to do so (ex. ConsumeKafkaRecord). InferAvroSchema can not be used here because the consume processor is the first processor of the flow and it needs the schema before even adding the infer processor. The other scenario where the InferAvroSchema is not useful is when data is transformed by the record processor (ConvertRecord, LookupRecord, etc). Indeed, schema inference should be done “inside” the processor to capture data changes. Otherwise, new field will be ignored.
Enter Schema Inference in Record Readers.
New Schema Inference capability in Record Reader
NiFi 1.9 adds the ability to Infer the schema while de-serializing data. This resolves the two aforementioned issues of the InferAvroSchema processor. Schema Inference is defined inside the Record Reader itself and can be used from the beginning of the flow. If the Record Processor transform the data, it will be able to infer the schema for the writer and detect new fields as well. A schema cache has been introduced to avoid inferring the schema for each flow file and to increase the performances.
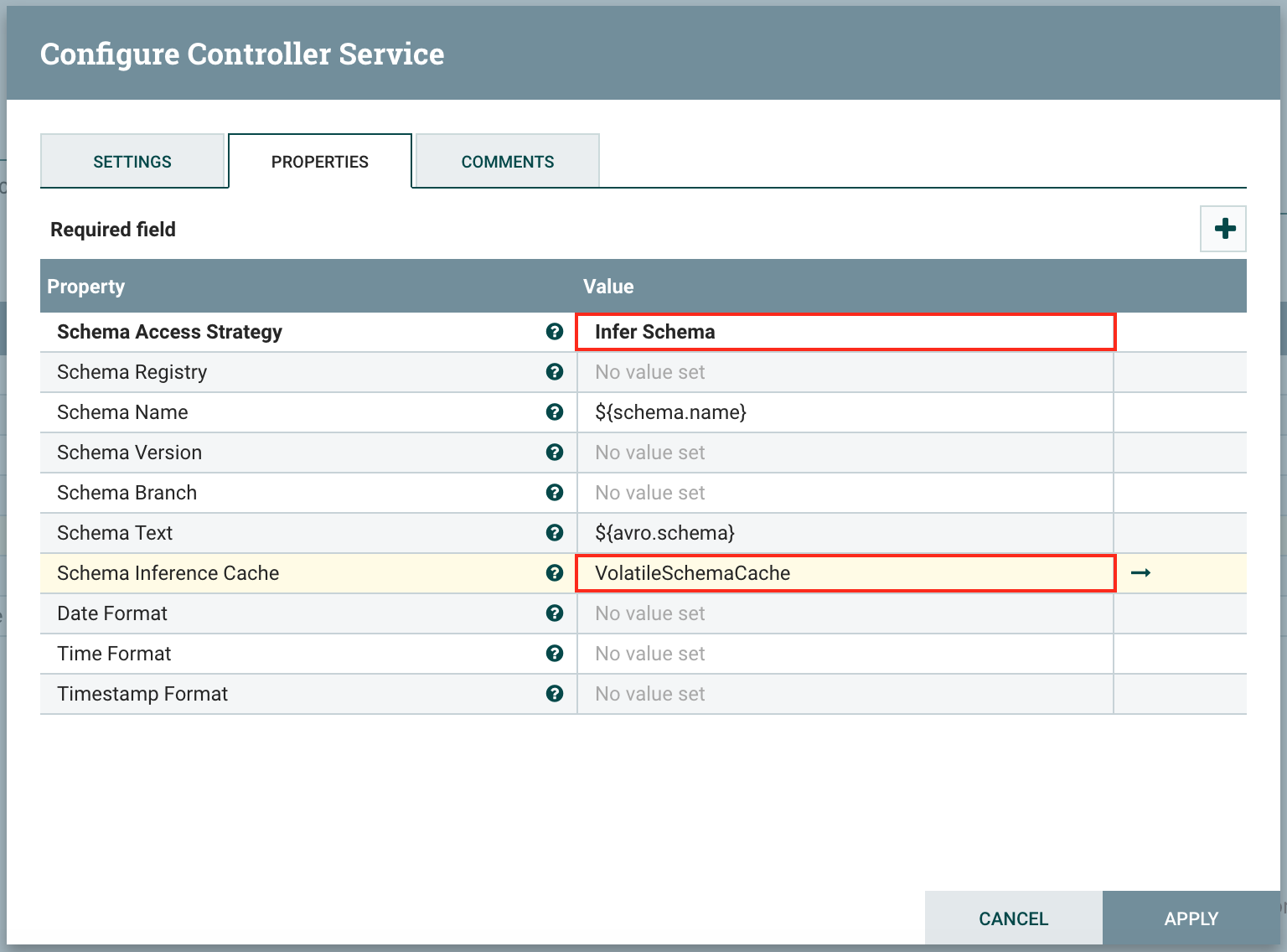
Thanks to this feature, dynamically inferring schemas of data coming from Kafka and using record processors can be done easily with one processor.
Conclusion
You have no more excuse to not use Record Processor now. They offer better performance, functionalities and they are easier to use now. This being said,defining schemas manually is also useful and won’t disappear. It especially important to enforce schema management rules and schema evolution.
Thanks for reading me. As always, feedback and suggestions are welcome.