
Best practices for running Apache NiFi in production: 3 takeaways from real world projects

Summary
DataWorks Summit (DWS) is the industry’s Premier Big Data Community Event in Europe and the US. The last DWS was in Berlin, Germany, on April 18th and 19th. This was the 6th year occurence in Europe and this year there was over 1200 attendees from 51 different countries, 77 breakouts in 8 tracks, 8 Birds-of-a-Feather sessions and 7 meetups. I had the opportunity to attend as a speaker this year, where I gave a talk on “Best practices and lessons learnt from Running Apache NiFi”. It was a joint talk with the Big Data squad team from Renault, a French car manufacturer. The presentation recording is available on youtube. In this blog, I’ll share with you the 3 key takeaways from our talk.
NiFi is an accelerator for your Big Data projects
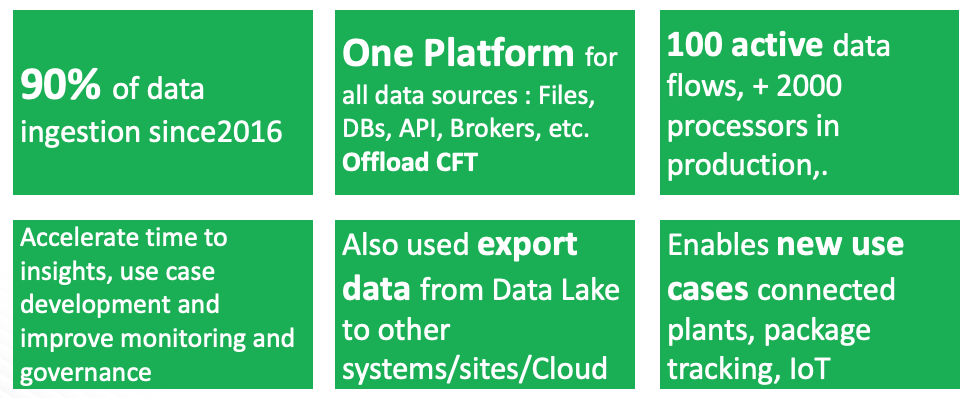
If you worked on any data project, you already know how hard it is to get data into your platform to start “the real work”. This is particularly important in Big Data projects where companies aim to ingest a variety of data sources ranging from Databases, to files, to IoT data. Having NiFi as a single ingestion platform that gives you out-of-the-box tools to ingest several data sources in a secure and governed manner is a real differentiator. NiFi accelerates data availability in the data lake, and hence accelerates your Big Data projects and business value extraction. The following numbers from Renault projects are worth a thousands words.
NiFi enables new use cases
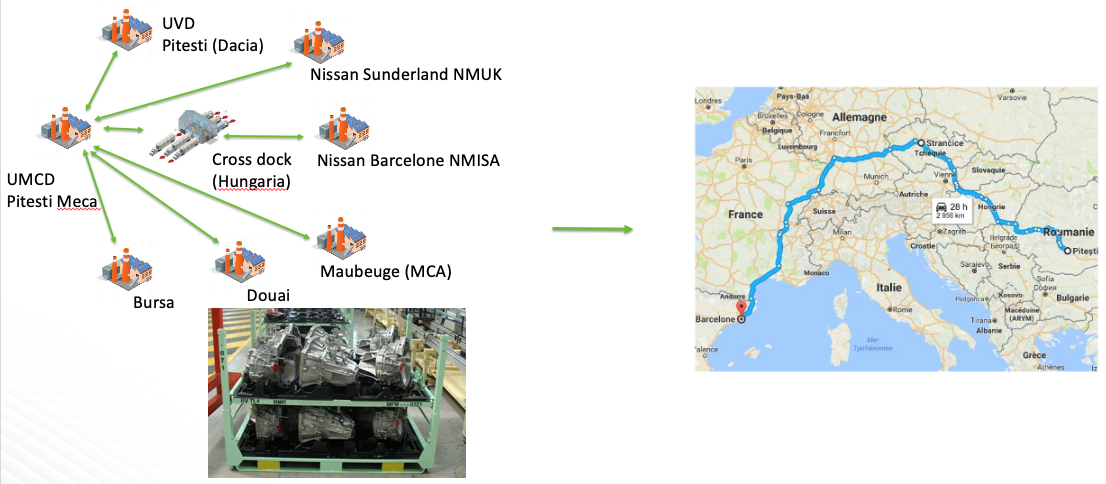
NiFi is not only an ingestion tool. It’s a data logistics platform. This means that NiFi enables easy collection, curation, analysis and action on any data anywhere (edge, cloud, data center) with built-in end-to-end security and provenance. This unique set of features makes NiFi the best choice for implementing new data centric use cases that require geographically distributed architectures and high levels of SLA (availability, security and performance). In our talk, two exciting use cases were shared: connected plants and packaging traceability.
NiFi flow design is like software development
When I pitch NiFi to my customers I can see them get excited quickly. They start brainstorming instantly and ask if NiFi can do this or that. In this situation, I usually fire a NiFi instance on my MAC and start dragging and dropping a few processors in NiFi to simulate their use case. This is a powerful feature that fosters interactions between team members in the room and gets us to very interesting business and technical discussions.
When people see the power of NiFi and all what we can easily achieve in short a timeframe, a new set of questions arise (especially from the very few skeptics in the room :)). Can I automate this task? Can I monitor my data flows? Can I integrate NiFi flow design with my development process? Can I “industrialize” my use case?. All these questions are legitimate when we see how powerful and easy to use NiFi is. The good news is that “Yes” is the answer to all previous questions. However, it’s important to put in place the right process to avoid having a POC that becomes a production (who has never lived this situation?)
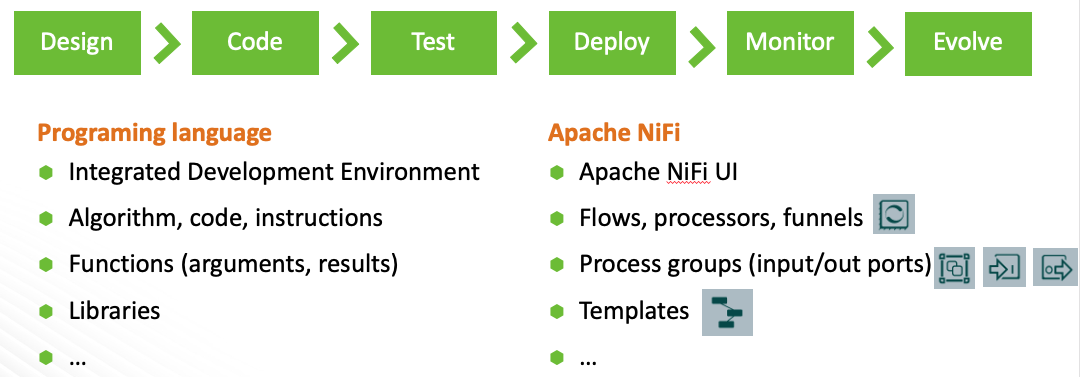
The way I like to answer these questions is to show how much NiFi flow design is like software development. When a developer wants to tackle a problem, he starts designing a solution by asking : ‘what’s the best way to implement this?’. The word best here integrates aspects like complexity, scalability, maintainability, etc. The same logic applies to NiFi flow design. You have several ways to implement your use case and they are not equivalent. Once a solution is found, you will use NiFi UI as your IDE to implement the solution.
Your flow is a set of processors just like your code or your algorithm is a set of instructions. You have “if then else” statements with routing processor, you have “for” or “while” loops with update attributes and self-relations, you have mathematical and logical operators with processors and Expression Langage, etc. When you build your flow you divide it into process groups similar to functions you use when you organize your code. This makes your applications easier to understand, to maintain, and to debug. You use templates for repetitive things like you build and use libraries across your projects.
From this main consideration, you can derive several best practices. Some of them are generic software development practices, and some of them are specific to NiFi as “a programming language”. I share some good principals to use in this following slide:
Conclusions
NiFi is a powerful tool that gives you business and technical agility. To master its power, it is important to define and to enforce best practices. Lots of these best practices can be borrowed directly from software engineering. Others are specific to NiFi. The recording from our Dataworks Summit is available an give more details on these best practices. If this article got you excited and you want to give NiFi a try, read the following tutorial to build an IIoT prototype with NiFi, MQTT and Raspberry Pi in less than one hour.