
Summary
One of the powerful features of Apache NiFi is the ability to design complex data flows with a user-friendly UI. This feature empowers users to easily design and test data flows in a short amount of time. However, the UI-based paradigm introduces challenges on industrializing these data flows. In this article, we will first explore why it’s important to adopt a process around your development lifecycle for flow design in NiFi. Then we will go through the reasons why existing tools are not suitable for data flows paradigms. Finally, we will introduce two new features added in NiFi 1.5 to support the development life cycle of data flow and show you how to use them in a simple practical use case.
Why do we need Flow Development Life Cycle?
Designing a data flow in NiFi is similar to writing code in your preferred langage. You need to define the algorithm that solves your problem in the most elegant and efficient way. You may potentially test different approaches and work incrementally towards your final goal. So you need to keep track of several flow versions and navigate between them easily. I can almost hear you say ‘Git’ ! but remember, we are designing data flows in a UI.
Once you are happy with your design, you need to validate its performance and behaviors in realistic settings before deploying it to production. You can use a test NiFi cluster with several nodes and stress your dataflow at scale. Here, you need to move the flow from the dev cluster into the test cluster, and later from the test cluster to the production cluster. Settings like hostnames, IP addresses, database names, passwords, etc. need to be dynamically changed when moving flows from one environment to another.
In software development, these tasks are handled by the SDLC process and a set of tools such as code versioning (e.g. Github) or automation tools (e.g. Jenkins). There are a few options to use these tools with NiFi but not without challenges. The first option is to leverage the flow.xml.gz file that stores the configurations of all data flows running in a NiFi cluster. This file can be versioned in a Git repository and deployed to several environments. The main challenge is that the flow.xml contains configurations of all flows in a given cluster, as opposed to having only the configuration of the flow being updated/developed. Touching all flows running in production when you want to do a slight change in one of the flows is not an acceptable solution.
Another option is to use NiFi templates to manage flows individually. With templates, one can design a flow, export it, version it with Github and deploy it to a new environment. Since NiFi has a nice REST API, this whole process can be automated with some effort. Even if this option is cleaner than the first one, it comes with its difficulties: dynamically changing environment-dependent settings, updating running flows, just to name a few.
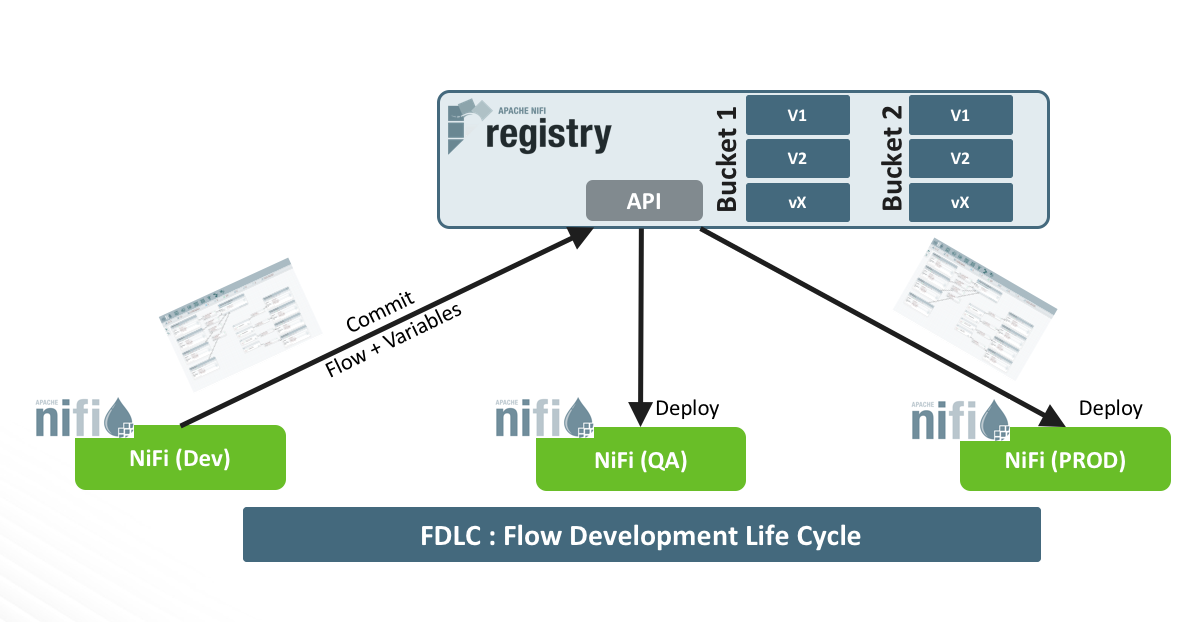
To make flow developers’ life easier, the NiFi community decided to work on these topics to provide native capabilities for flow deployments. I like to call it Flow Development Life Cycle (FDLC) capabilities. These capabilities are Flow and Variable registries.
- Flow Registry: a subproject of Apache NiFi that provides a central location for storage and management of shared resources across one or more instances of NiFi and/or MiNiFi. It supports storing and managing versioned flows and integrates with NiFi to allow storing, retrieving, and upgrading versioned flows . Simply put, it is the Git of NiFi (there, you have it!). Flow registry has been integrated with NiFi starting from version 1.5 (NIFI-4435).
- Variable Registry: provides users with flexibility to dynamically create variables and refer to them in component properties. It not only simplifies configuration through value reuse, but also improves portability of flows to new environments. The management of these variables is done via the NiFi UI at a process group level. These variables can be updated at runtime without restarting NiFi. This is a great improvement compared to the previous file-based variable registry. Variable registry is available starting from NiFi 1.4 (NIFI-4224).
Let’s get started !
NiFi registry setup
Let’s start by downloading and starting NiFi registry:
1
2
3
wget http://apache.crihan.fr/dist/nifi/nifi-registry/nifi-registry-0.1.0/nifi-registry-0.1.0-bin.tar.gz
tar -zxf nifi-registry-0.1.0-bin.tar.gz
./nifi-registry-0.1.0/bin/nifi-registry.sh start
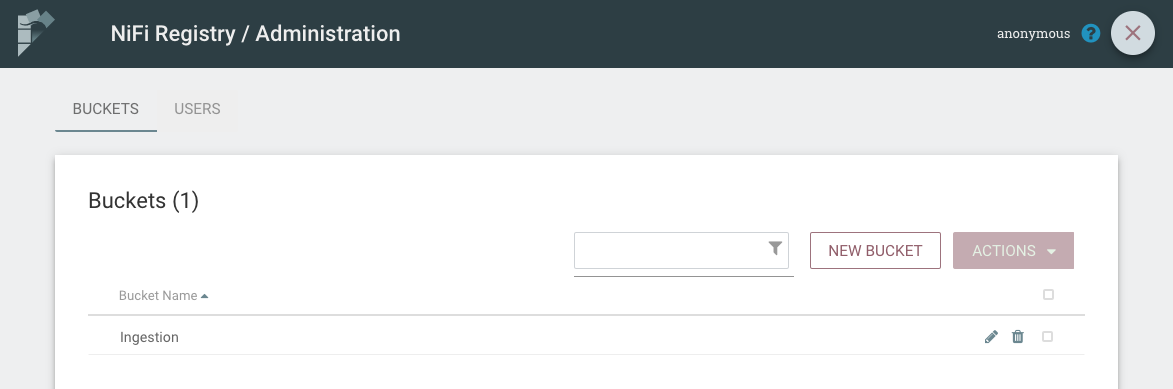
After startup, Registry UI is available at http://registry:18080/nifi-registry/. Click on the tool icon at the top right side of the UI and then click on NEW BUCKET. A bucket is equivalent to a repository in Github language. It’s just a container to organize your flows. Let’s call our new bucket “Ingestion”.
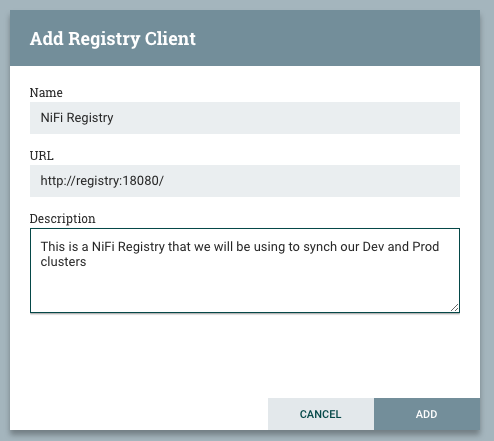
Let’s assume that we have 2 NiFi 1.5 instances that we will use for developments and production environments. To connect a NiFi instance to the flow registry, click on the Hamburger menu at the top right side of NiFi UI, click on Controller Settings, Registry Client, then add. Set the registry client with the registry address and give it a name. Repeat the same steps for the second NiFi instance.
Developing and versioning a flow
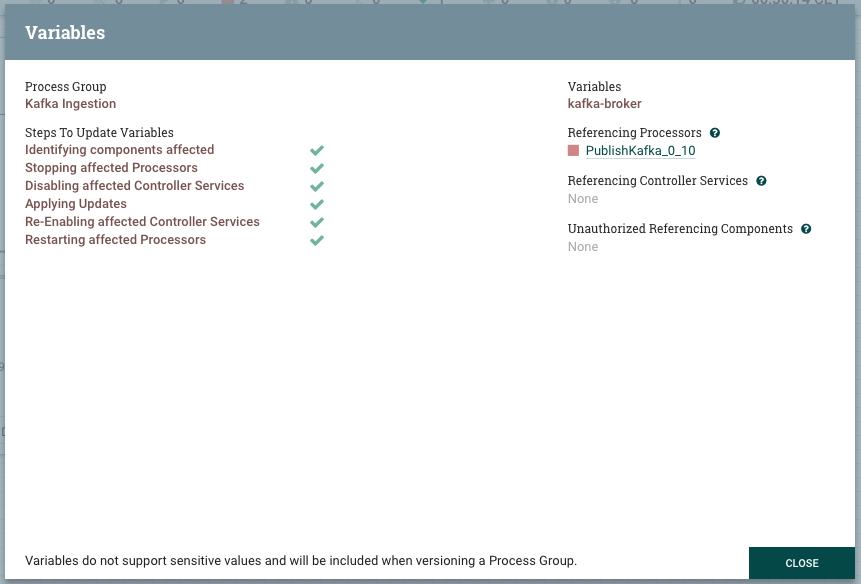
To test the features of the flow registry, let’s use the Dev instance and design a simple flow that generates dummy data and push it to Kafka. First, start by creating a new process group and name it “Kafka Ingestion”. Since our Kafka broker is different when we are in Dev and in Prod, we will use variables for broker host, port and topic name. To do so, right click on the process group, then variables, then “+” button. Add 3 variables as follows.
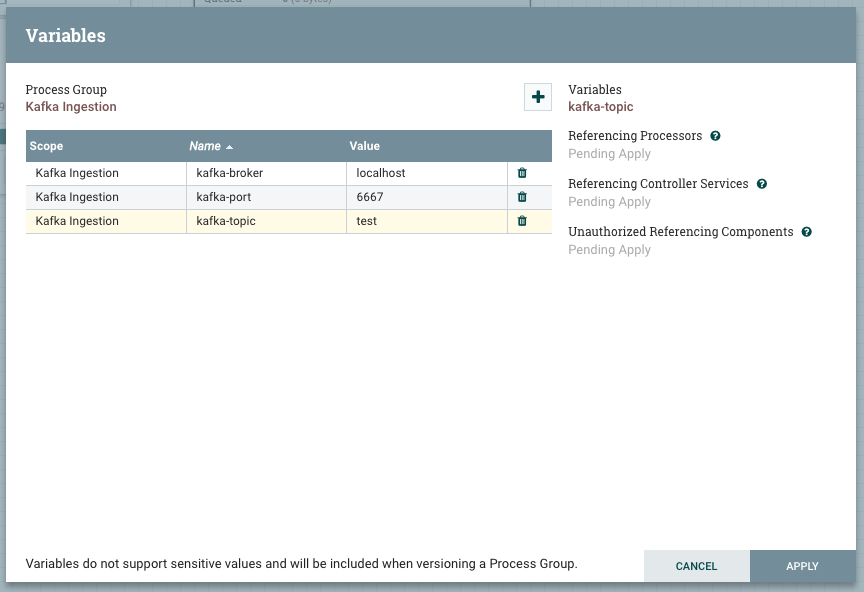
These variables are handled by the NiFi framework and stored in the flow definition file (flow.xml). There is a ‘variable’ section at the end of each process group section that lists the defined variables and their values. From a user experience perspective, you can add/update/delete variables without having to restart your NiFi instance.
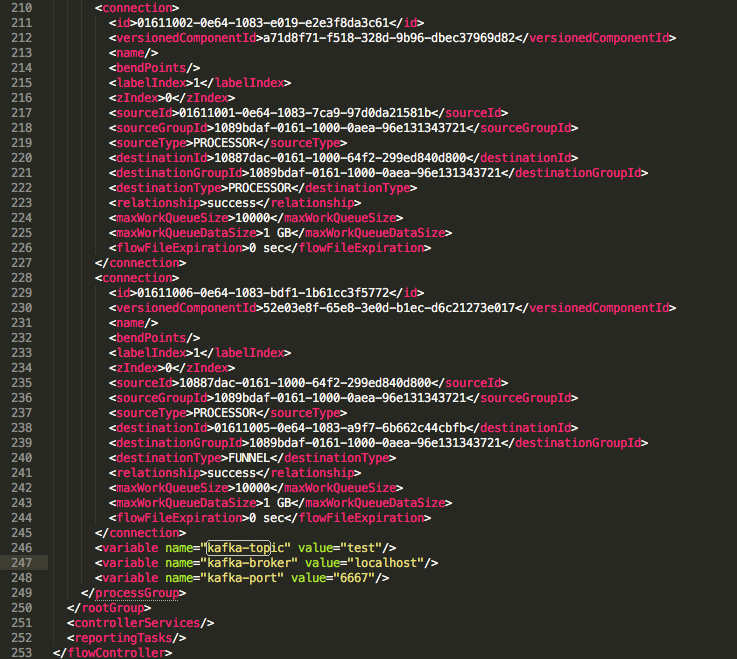
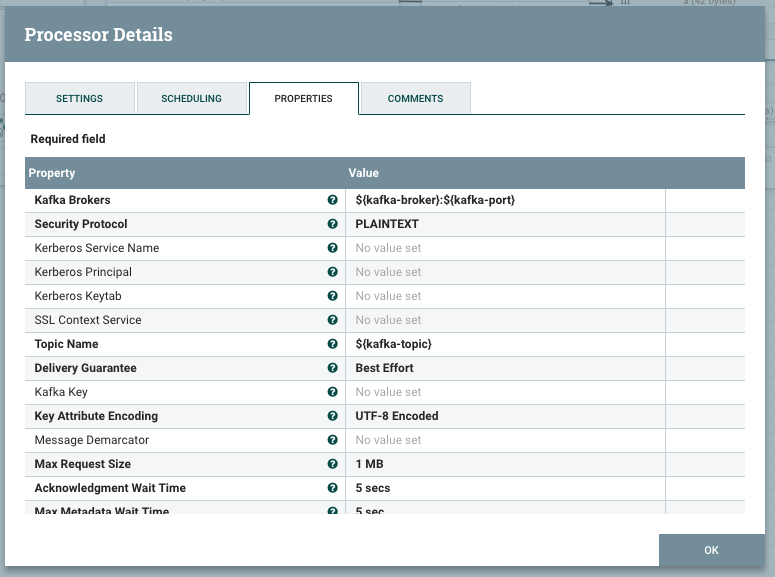
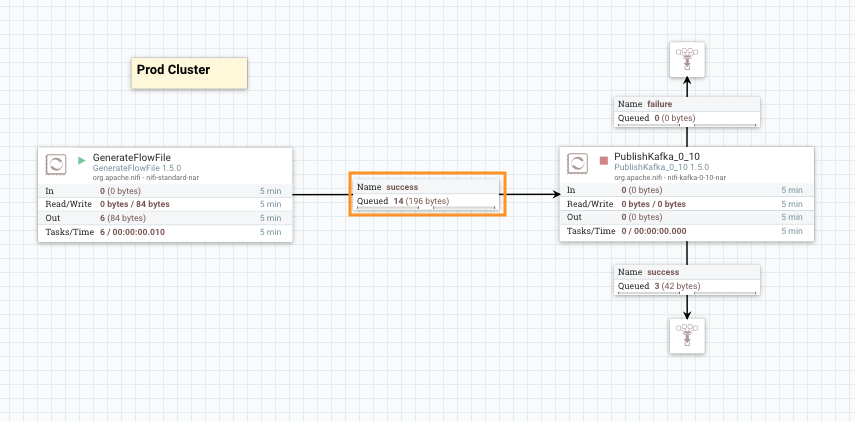
Now add a GenerateFlowFile, set its scheduling to 120 seconds and Custom Text property at any string you like. Add a PublishKafka_0_10 and configure it as follows (note the use of variables ${kafka-broker} ${kafka-port} and ${kafka-topic}).
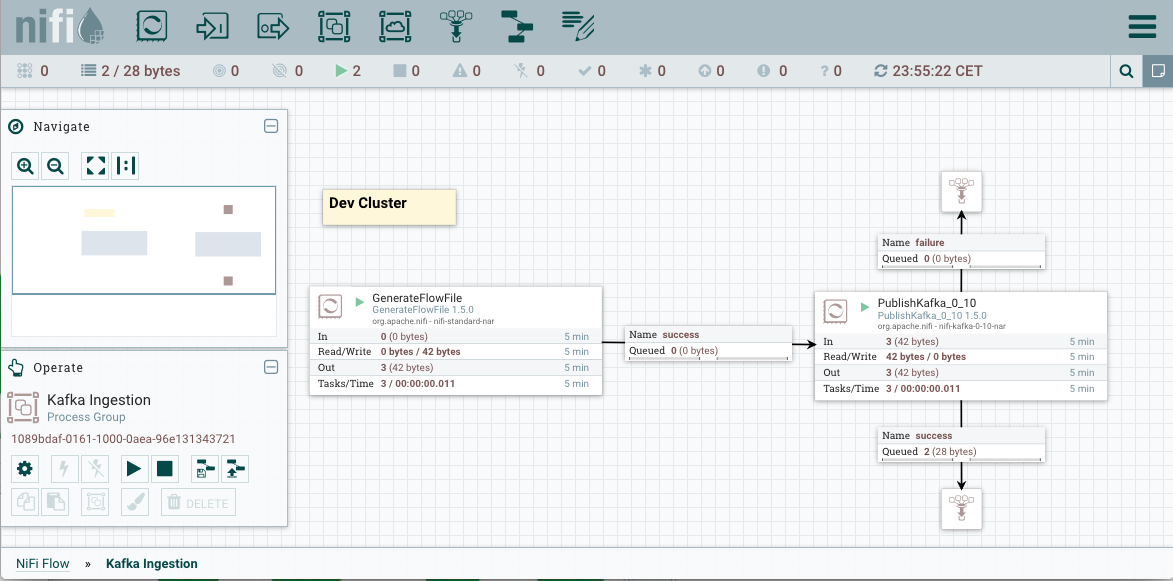
Connect and start the two processors as illustrated in the picture below. Since we have a local Kafka broker instance with a topic “test” already created, we can see data going to success relationship.
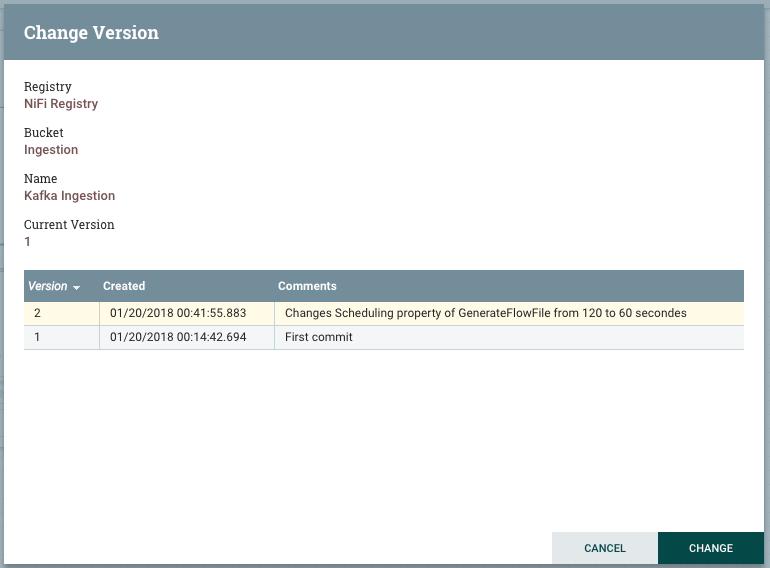
To save our flow in the flow registry, let’s navigate to the root process group, right click on “Kafka Ingestion” process group, version, and start version control. We end up with a window where we are prompted to set the flow name, flow description and version comments. Click on save, and that’s all. Your flow is saved, versioned, and ready to be deployed elsewhere.
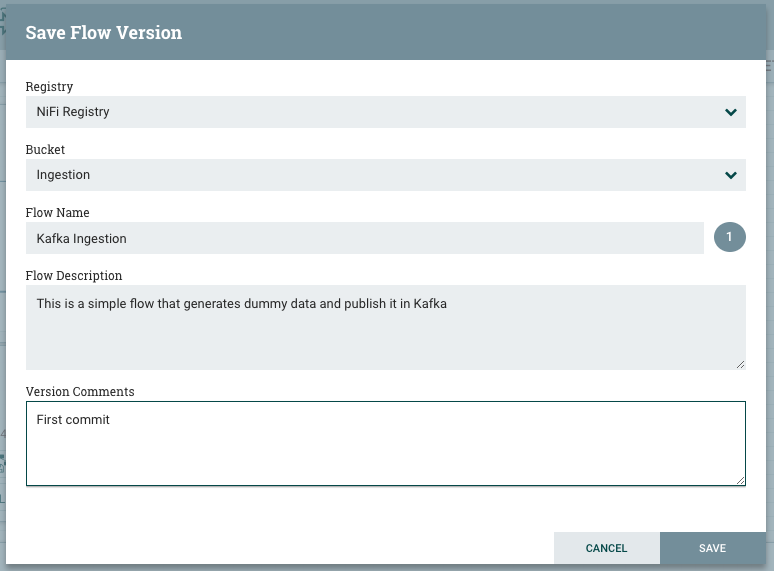
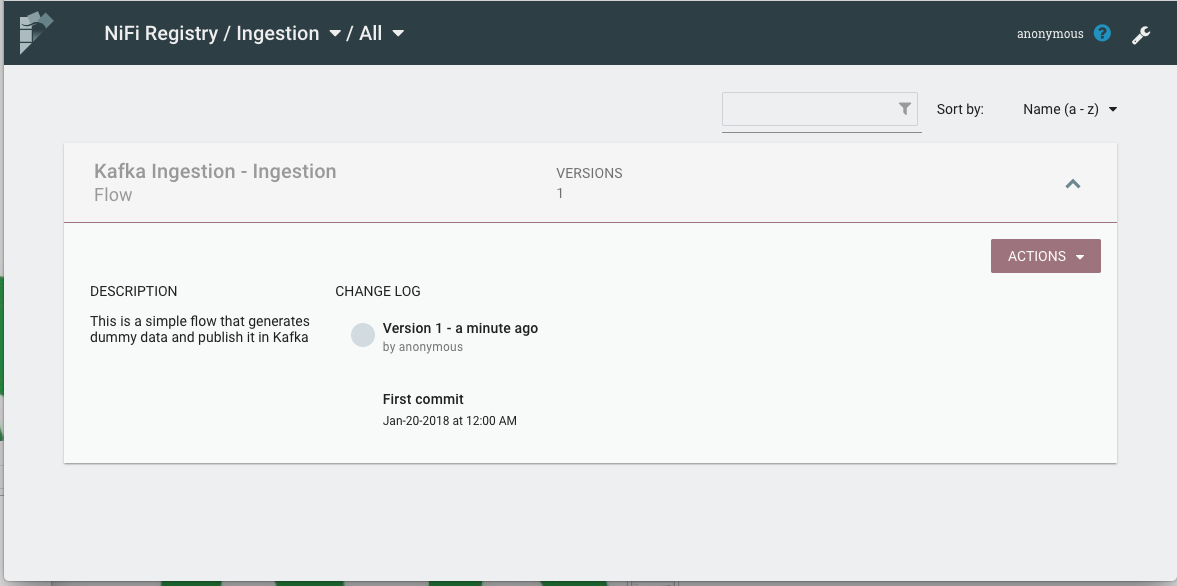
Navigate to the registry UI to check that the flow has been published with its information.
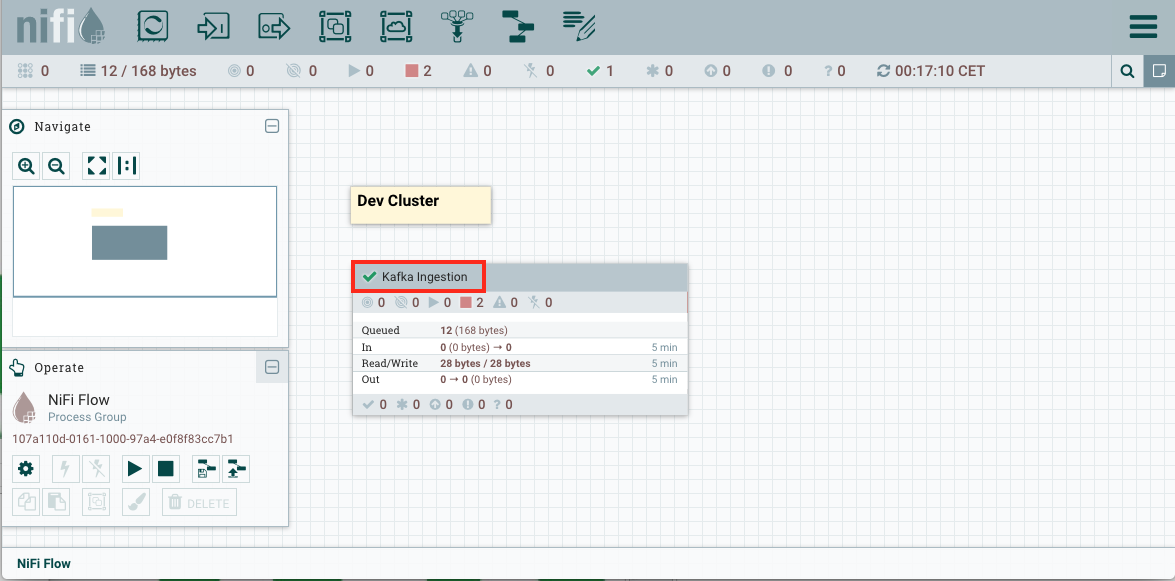
You can also notice that the visual aspect of the process group has changed. There’s now a green checkmark now that indicates that the process group has the last version available in the Flow Registry, as illustrated in the picture below.
Deploying the flow to production
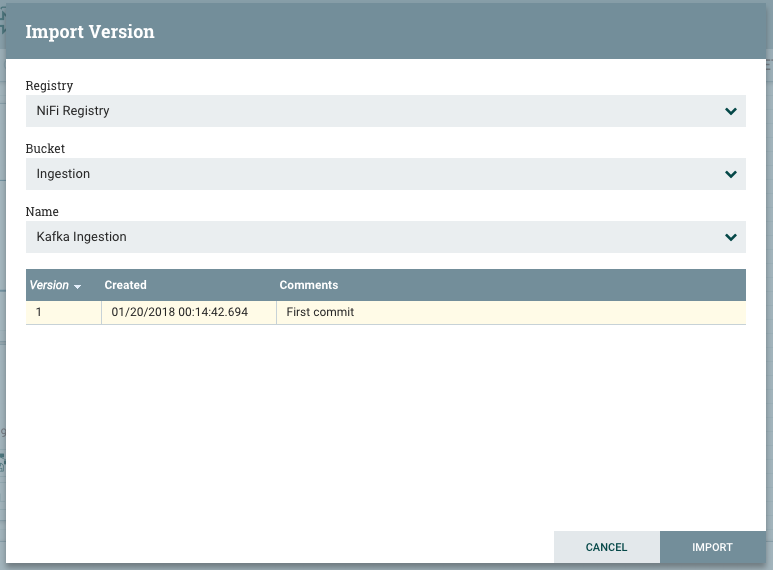
To deploy this flow in production, simply add a new process group in the production cluster, click on Import link, and select the flow you would like to import. The flow now is deployed on the production cluster and is ready to be started.
Before starting the process group, click on variables and change the variables to match your production environment settings. For instance, change kafka-broker from localhost to hdpcluster.hortonworks.com. NiFi takes care of stopping the affected components, applying updates and restarting those components: a neat way for updating these variables. As the below picture shows, only Publish_Kafka_0_10 is affected by this operation.
Now we can start the process group to have the flow running in production. Take your time to get that coffee :)
Updating the flow in dev and production
Let’s now consider that we need to update our flow. Let’s come back to our Dev instance and change the scheduling of the GenerateFlowFile from 120 seconds to 60 seconds.
We can see that the process group has a gray star icon, that means it’s no longer in sync with the flow registry. To commit these changes to the flow registry, click on Version, then commit local changes. These changes are now visible at the flow registry with all the details provided with the commit.
To deploy this new version of the flow in the production cluster, go back to the production cluster. You will see the red icon on the process group letting you know that a new version of the flow is available. Right click on the process group, select versions and then choose the last version available. The new flow is deployed for you. Notice that existing variables are not affected by this update.
If we had a new variable defined in this version, its name and value would have been sync-ed to the production cluster.
Final thoughts
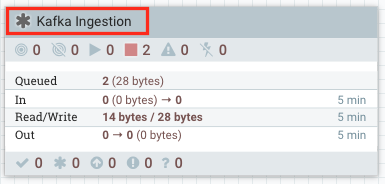
In addition to the smooth user experience that NiFi Flow and Variable registries bring to the deployment process, they help keeping the flow in a coherent state. Let’s consider the case where the production cluster has several flow files in the queue between GenerateFlowFile and PublishKafka.
What happens if I add an UpdateAttribute between these two processors in Dev and then commit this update to production? NiFi will elegantly move the queue and its data between the GenerateFlowFile and the UpdateAttribute.
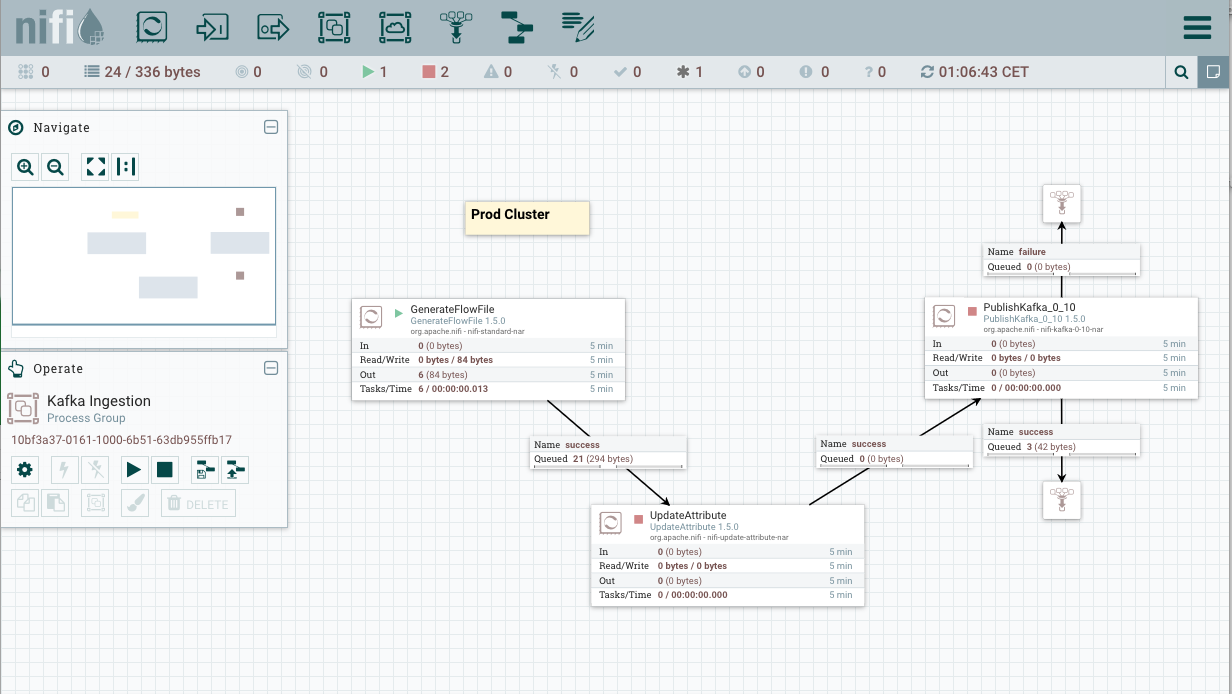
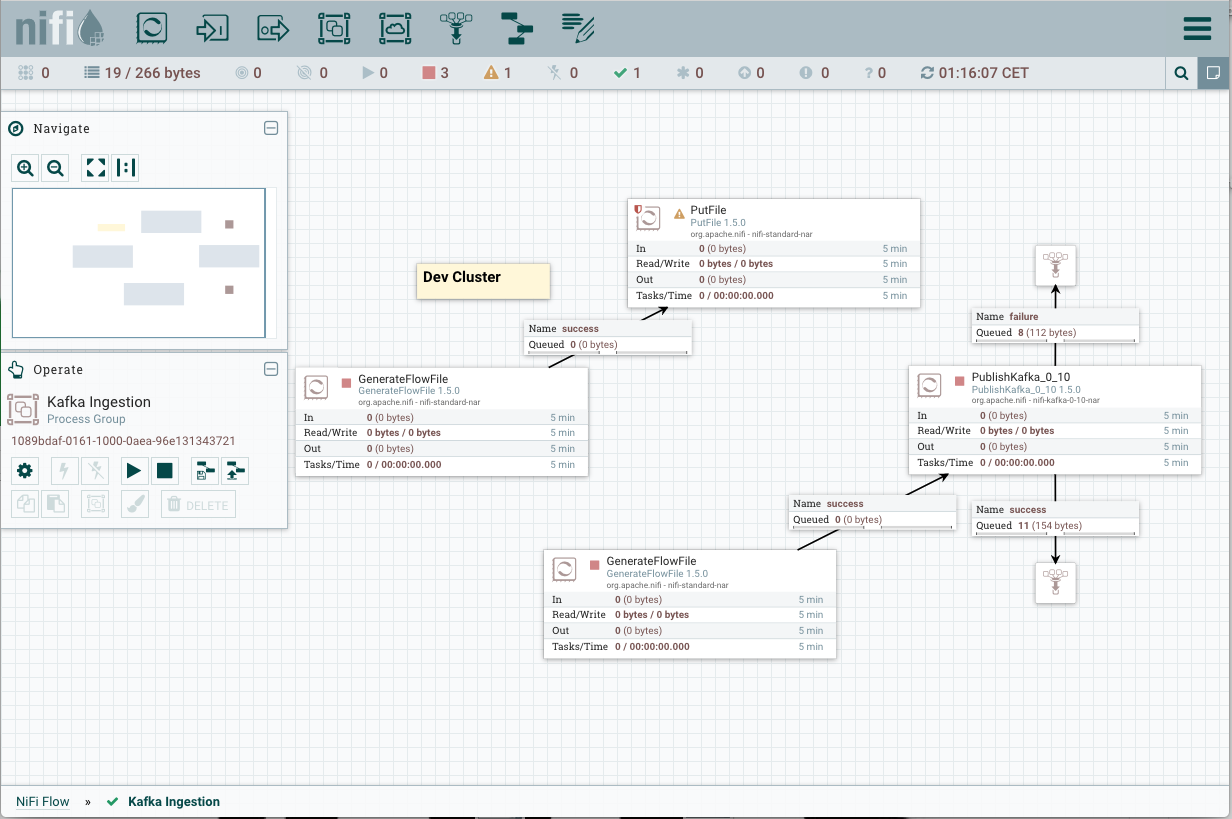
In some situations, the updates from Dev to Prod cannot be applied without losing data. Let’s consider a similar scenario where some data is still in the queue between the two initial processors while some breaking changes have been applied in Dev and committed to the flow registry.
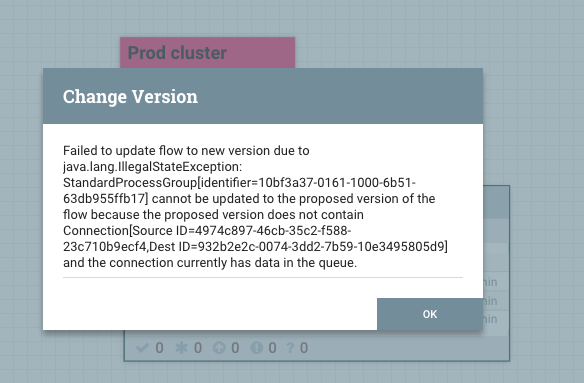
When we try to commit these changes to production, it fails with an IllegalStateException. This is because an existing connection has been deleted from the flow, where it actually contains data in the production cluster. Once the data is consumed out of the queue, the new version of the flow can be used. This control protects us from deleting data by mistake. These situations are impossible to manage with legacy approches such as versioning flow.xml or using templates.
Useful links
- https://nifi.apache.org/docs/nifi-docs/html/user-guide.html
- https://community.hortonworks.com/articles/60868/enterprise-nifi-implementing-reusable-components-a.html
- https://cwiki.apache.org/confluence/display/NIFI/Extension+Repositories+%28aka+Extension+Registry%29+for+Dynamically-loaded+Extensions
Thanks for reading me. As always, feedback and suggestions are welcome.