

The Apache NiFi community did an amazing job working on improving NiFi and adding new features. Apache NiFi 1.10 comes with 360+ Jira closed with big improvements/new features sections. Numerous bugs have been resolved too, which makes NiFi more robust.
In this blog, we will focus on a simple new feature, actually a processor, that makes your flow development easier when it comes to errors handling.
Error handling before Apache NiFi 1.10
One of the cool features of NiFi is error handling. For each processor that can fail, we have different relations. If I am trying to publish an event to Kafka, I can decide what to do in case of successful or failed operation.
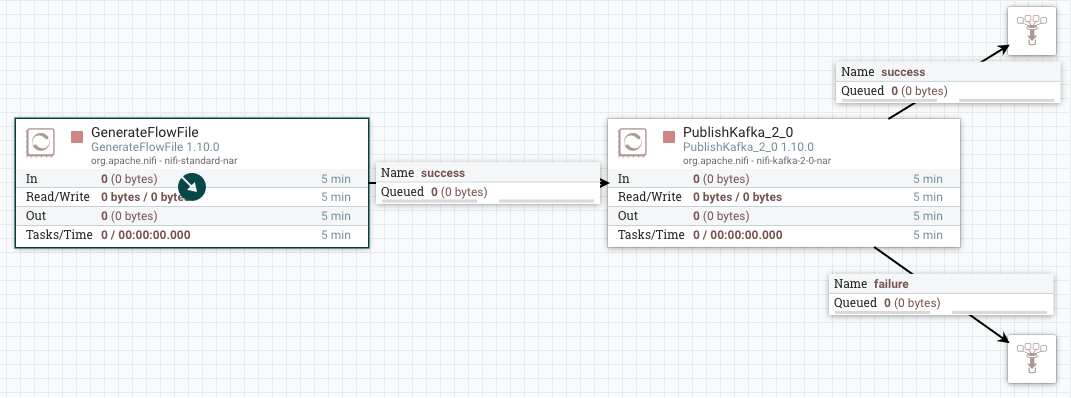
In a more realistic scenario, we auto-terminate the success relation since the event is persisted in the destination data store. For the failure relation, more work need to be done. There’s a well know pattern called “Dead Letter Queue” where events with errors are stored in a different destination than the target data store. HDFS, S3, local file or a monitoring tool are example of error destination stores for a DLQ.
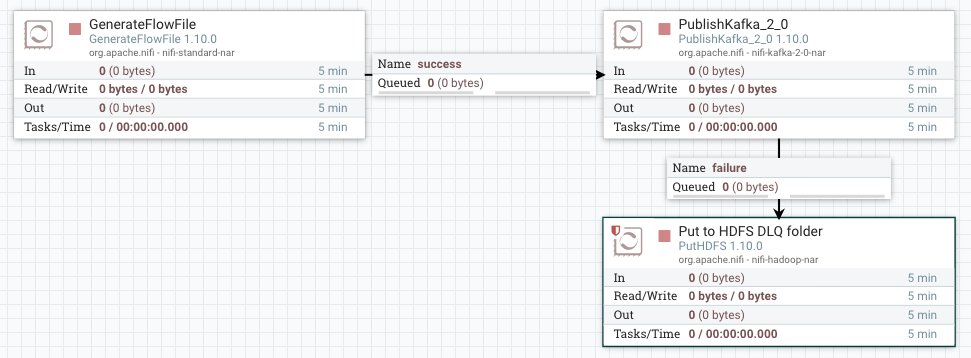
The error can be anything: destination not reachable, event data not compliant with a schema, etc. Some of these errors are a one time thing that resolves itself. Think about a network failure due to a packet loss or a hardware restart. If we try to publish the event again after few seconds we may be able to successfully write it to Kafka. NiFi supports reflexive loops where we can connect the failure relation of a processor into the incoming queue of the processor itself. This is not a good idea in general. If the issue is permanent (eg. Kafka broker lost), events go through an infinite loop. A better solution is to try to publish to Kafka several times (5 for instance), then send to the DLQ if the failure persists. To do this, we can use an UpdateAttribute to add a retries attribute that we increment every time the flow file goes through the failure relation. Then, we use a RouteOnAttribute to check if we exceeded the threshold that we defined or not. The flow looks like the below:
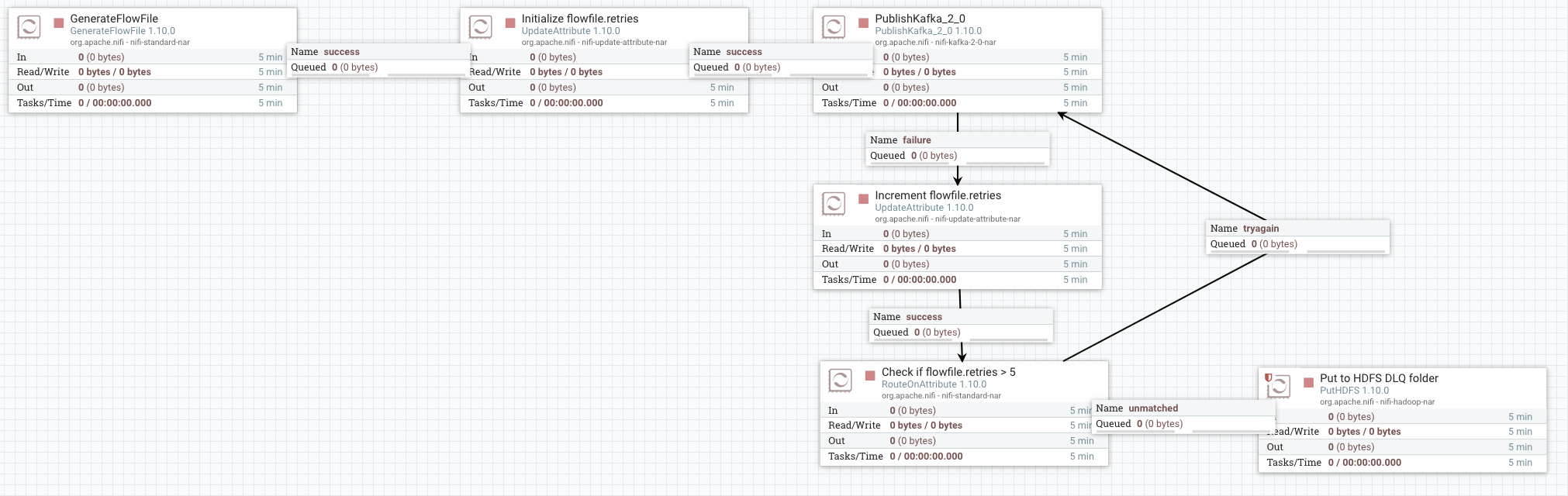
This is pretty simple, but doing this at scale can quickly becomes a complex. We can also use a process group to handle several error situations but not errors are equal.
What NiFi 1.10 brings to the table?
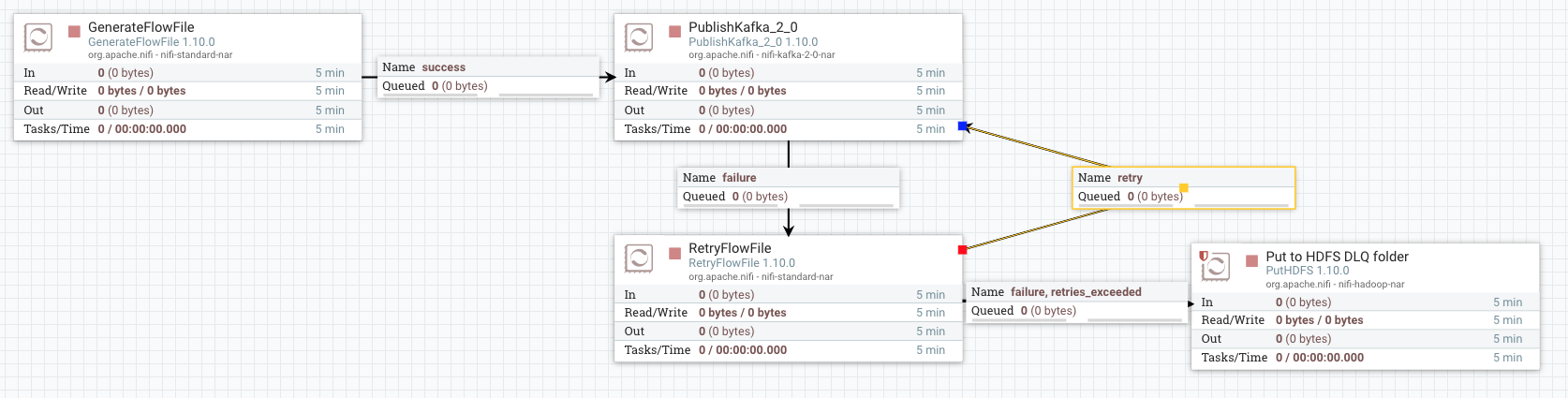
NiFi 1.10 has a new processor called RetryFlowFile (NIFI-6387) that makes error handling simpler. This processor implements the same strategy described previously. It replaces the two UpdateAttribute and the RouteOnAttribute processors and makes the configuration easier. Below the description of the processor extracted from the processor documentation:
FlowFiles passed to this Processor have a ‘Retry Attribute’ value checked against a configured ‘Maximum Retries’ value. If the current attribute value is below the configured maximum, the FlowFile is passed to a retry relationship. If the FlowFile’s attribute value exceeds the configured maximum, the FlowFile will be passed to a ‘retries_exceeded’ relationship.
The processor can also penalize each flowfile to make it wait for some time before trying again. This is very helpful as the issue may take some seconds to resolve itself. Below is how the RetryFlowFile processor should be configured to implement the same use case. The penalty duration can be configured in the settings tab and is set to 30 seconds by default.
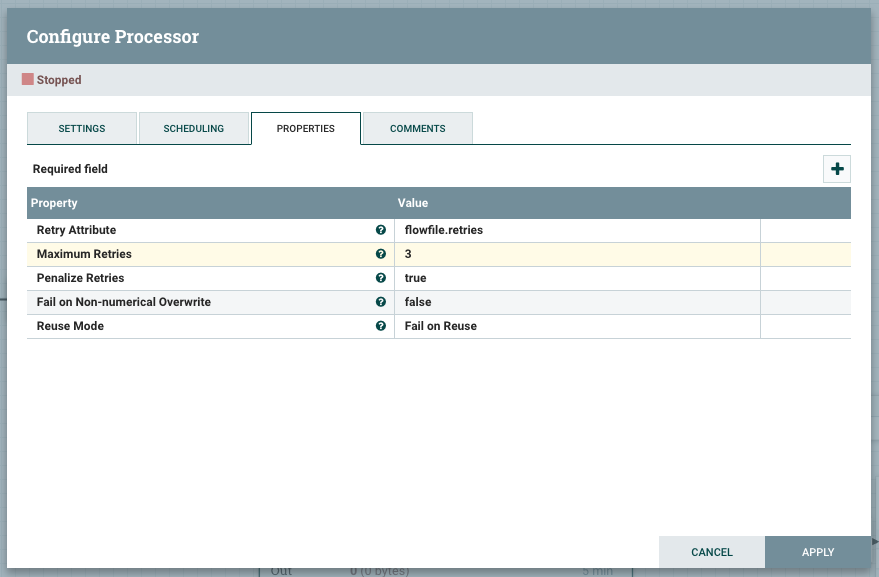
The end to end flow is now cleaner and simpler to develop.
Conclusion
NiFi 1.10 brings a set a new features and improvements. In this blog, we introduced a simple, yet useful, new processor that makes errors handling easier and cleaner. In the next blog, I’ll cover Site-To-Site and how NiFi 1.10 makes it easier to use by accepting input ports at any level
Thanks for reading me. As always, feedback and suggestions are welcome.
Post photo designed by Andrik Langfield on Unsplash